

What is Data Mining? Cases, analytical methods, introducing the application in the field of Healthcare
Data mining is a methodology where analytical techniques such as market basket analysis or clustering are applied to extract meaningful learnings from very large datasets.
This article provides an overview, the history and the methods used in data mining. The explanation of analytical methods is supported by the description of concrete application cases.
What is Data Mining?
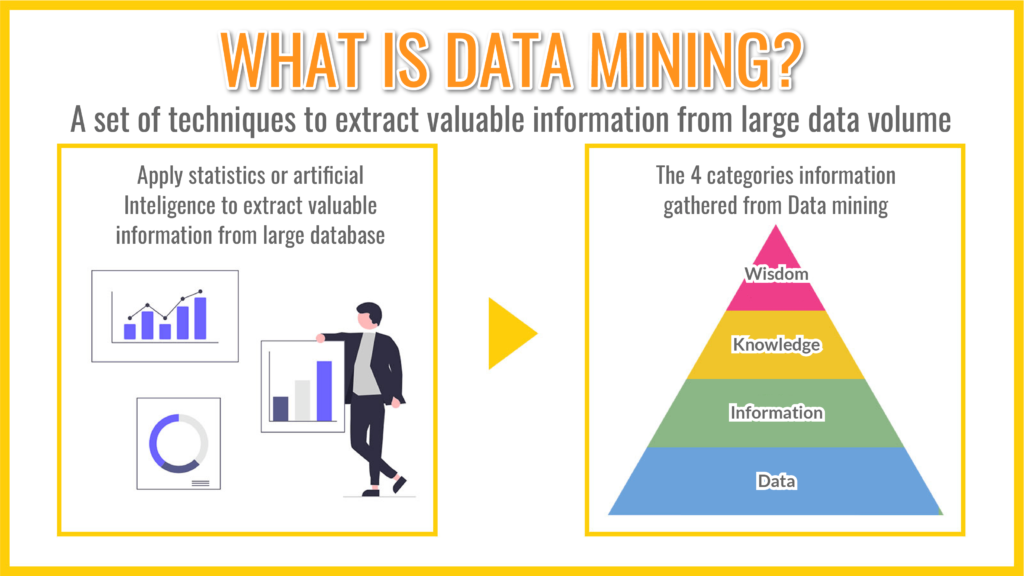
As the words seem to indicate, data mining is literally the method of digging into large volume of data to extract information and elaborate assumptions.
Useful information can be extracted by comprehensively applying techniques such as statistics, artificial intelligence (AI), and pattern recognition to a huge amount of structured data (big data).
A brief history of Data mining
The academic research field “Knowledge Discovery in Databases” established in 1989 is said to be the originator of data mining. “Knowledge Discovery in Databases”, also known as KDD, is the extraction of useful information from vast amounts of data using mining techniques.
In the 1990s, the performance of computers improved significantly. This also helped the acceleration of research on “Knowledge Discovery in Databases”. Researchers were able to propose data mining definitions, basic performance, and processing procedures.
Entering the new millennium, access to Internet by a growing number of households stimulated the development of new techniques to handle the huge volumes of data generated by Internet activities. Such development mostly originated from IT corporations and then progressively expanded into a field of its own with new companies focusing on analytics, especially with the surge of SNS.
What are the main types of data mining?
There are two types of data mining: “hypothesis verification” and “knowledge discovery”.
Below, we will explain “hypothesis verification” and “knowledge discovery”.
- Hypothesis verification
Hypothesis verification is to collect data necessary for solving problems and events that you want to verify based on a hypothesis made in advance and analyze it by an appropriate method.
It is up to humans to make hypotheses and select analytical methods to obtain the desired analytical results. Therefore, a person with knowledge of statistics is required. However, some data mining tools may add expertise.
Hypothesis testing is based on hypotheses, so unexpected results are unlikely to come up. However, the initial hypothesis might be wrong. Therefore, it is important to repeat the verification and analysis of the hypothesis, then repeat the interpretation of the analysis results. In the actual analysis field, it is common to combine various analysis methods to generate results.
In addition, as a data mining method for hypothesis verification, there are “quantitative variables” that estimate sales and sales volume, for example which products are sold in which regions and how much, and “qualitative variables” that extract, classify and organize products and product categories that are sold by region. - Knowledge discovery
Knowledge discovery automatically discovers new patterns, rules, similarities, and other knowledge from data collected without making hypotheses in advance.
Knowledge discovery is effective for big data and is mainly used in “machine learning”. Machine learning utilizes artificial intelligence (AI), and the computer itself learns and derives correlations. AI makes it possible to discover correlations that humans do not anticipate or overlook.
It is also possible to identify the cause of an event and optimize issues involving complex conditions. However, if the data as such are not relevant, it would be hard to get useful results.
Data mining methods for knowledge discovery include “clustering” that divides data into groups and “market basket analysis” that finds relationships in data.
What do you get from data mining?
There are fundamentally 4 categories of knowledge that derive from the practice of data mining:
- Data: Numerical values that have not been organized or classified
- Information: Data organized and classified
- Knowledge: Trends and findings obtained from information
- Wisdom: People make decisions based on knowledge
The information obtained by data mining is called “DIKW model”, the acronym of the 4 categories above. Information is more useful than data, knowledge is more useful than information, and wisdom is more useful than knowledge.
Data mining can be used to collect, organize, classify, and acquire knowledge, but it requires human judgment to utilize the acquired knowledge as wisdom.
The 3 things you can achieve with Data Mining
Data mining makes possible three decisive actions with data: classify data, predict data and discover relations across data.
1. Classifying Data
It is important to set conditions to classify and organize the collected data. For example, you can sort and organize products by sales volume, sales amount, net profit, and so on.
Some people think of this as “just dividing by group”, but the amount of original data handled by data mining is enormous. It will be difficult to manually divide a huge amount of data into groups. The ease of handling information differs greatly depending on whether a huge amount of data is arranged in a disorderly manner or if it is classified and organized by group.
Information can be easily used just by classifying and organizing data, which has the advantage of making it easier to think about marketing measures.
2. Discovering data correlation
From the collected data, it is possible to discover relationships between data such as concurrency and correlation.
By performing data mining, you can find out which products are purchased at the same time and which products whose sales increase at the same time. In some cases, the relevance of products that people did not notice and the effects of seasons and weather may be revealed.
3. Data forecasting
By analyzing the events and relevance of the collected data, we clarify the probability and factors that cause a specific event to occur. For example, if you have a product that sells in the cold, you can expect sales to increase from autumn to winter. Also, if product A and product B sell together well, it is possible to predict that new product C similar to product B, may also sell with product A.
There is a big difference between making an intuitive prediction and making a prediction based on the collected data. For example, in the case of “hot coffee sells when it gets cold” and “hot coffee sells when the temperature drops below XX degrees Celsius”, the latter, which has the facts that are the basis of the prediction, can be a more accurate strategy.
Some examples of application
Data mining is used in various industries, here are a few examples in some representative segments.
Retail Business
In the retail industry, the information obtained from data mining may be used in marketing planning.
By analyzing customer data, weather, days of the week, time zones, sales performance, etc., it is possible to understand when and what products are sold and how much. From this information, you can take an effective approach, such as adjusting the purchase time and quantity of products.
In addition, some retailers use push notifications on their smartphones to recommend products that suit their customers’ tastes or deliver campaigns by direct mail.
Manufacturing industries
In the manufacturing industry, data mining is mainly used for equipment management in manufacturing operations. For example, it is possible to understand when, where, and at what timing a defect or failure is likely to occur. Therefore, inspections and equipment replacements can be performed at the appropriate time in anticipation of failure. Furthermore, if this analyzed information is utilized at the stage of designing manufacturing equipment, it might be possible to make equipment that is not only hard to break down but also more efficient.
Finance Industry
In addition to customer data, financial institutions hold multi-billion yen transaction data. By mining these data, it is possible to detect unauthorized use such as theft and skimming. If a problem arises, it is possible to contact the customer immediately to check the situation, avoid risk and solve the problem quickly.
In addition to promoting sales of financial products such as loans and investment trusts to prospective customers, it is also possible to predict cancellations of existing customers and take countermeasures accordingly. In addition, it is possible to obtain an accurate picture of market risk and predict the probability that a lender will default.
Education
By analyzing the progress of learning and the results of tests, it is possible to understand the subjects and contents that students are good at and weak at, and the degree of understanding of each student. It is also possible to group students according to their level of comprehension, provide guidance according to their level, and consider individual measures to improve their grades.
Data mining can also help you predict how your current student performance will change in the future.
Insurance
Data mining is also used in the insurance industry, such as life insurance and non-life insurance.
For example, in the case of life insurance, we analyze the gender and age of customers, illness, morbidity, days to recovery, medical expenses, and so on. In the case of automobile insurance, the probability of an accident, the age of the driver, the type and grade of the automobile, the amount of damage compensation, etc., were analyzed. In the case of fire insurance, we analyze the probability of a fire, the number of years of residence, insured items such as the damaged housing / household goods and restoration costs.
By analyzing these data, it is possible to understand the relevance and use of the appropriate insurance product and to calculate insurance premiums.
How to perform data mining
Data mining is performed in the order of collection, processing, and analysis.
1. Collecting the data
First, it is essential to collect data for data mining.
The more data you have, the more credible information you can get, so the point is to collect as much as possible. However, it does not mean that you need to collect a large amount of data. By collecting data that suits your purpose, you can perform data mining efficiently.
First, decide on the purpose of data mining, and then try to collect data that suits your purpose.
2. Processing the data collected
Immediately after collection, the data contains noise that interferes with the analysis. In addition, data cannot be read unless it is in a fixed format. Therefore, it is important to perform “data cleansing” to remove noise and unify the data format.
3. Analyzing the data
Data analysis is performed using methods such as “clustering,” “logistic regression analysis,” and “market basket analysis,” which will be described later.
After the analysis, we will identify the factors for the analysis results and verify whether they apply to other data.
The 3 most representative methods of analysis related to data mining
In data mining, methods such as “clustering”, “logistic regression analysis”, and “market basket analysis” are the most frequently used.
1. Clustering Analysis
Clustering is a technique for grouping data based on similarity. Each separated group is called a cluster.
Clustering is a commonly used technique for creating customer segments. Clustering makes it possible to develop effective campaigns for specific customers and introduce products and services.
2. Logistic Regression Analysis
Logistic regression analysis is a method of predicting the probability that a particular event will occur. For example, predict the probability that a customer will buy when you deploy a campaign.
Since it is only a prediction, it may differ from the actual result, but it is better to make a prediction so that measures to limit waste and optimize outcome are implemented.
3. Market Basket Analysis
Market basket analysis is a method of discovering combinations of products that are purchased together.
By conducting a market basket analysis, not only relevance such as “customers who buy hamburgers buy french fries together” but also unexpected relevance such as “customers who buy diapers also buy beer” can be found and can influence commercial strategy.
How about using data mining in the medical field?
By utilizing data mining in the medical field, we observe that the obtained learning can apply in various situations such as medical care or research.
For example, “Patients with illness A may also develop conditions C” and “Patients with characteristics A may develop illness B”. By data mining, it is possible to discover the treatment methods that others have elaborated only through intuition and experience. Some unexpected relevance appears that no one has ever imagined. It may therefore guide even an inexperienced doctor to make an accurate diagnosis.
In addition, by analyzing the number of patients, disease patterns, prescription volume of drugs, and prescription days, it is possible to understand drugs with a large number of concomitant use and comorbidities. Pharmaceutical companies and medical material / equipment manufacturers can apply this information to market situations such as drug prescription trends and market analysis. It can also be used in development fields such as field surveys and understanding the current status of the treatment efficacy compared with the developed items.
Medical Data Vision Co., Ltd. provides tools and services that support data analysis for medical institutions and pharmaceutical companies. Based on Japan’s largest medical care database, customers can analyze the number of patients, prescription days, prescription amount, etc. by themselves. If you are considering using data for marketing or development, please feel free to contact us.
For More Information, Please Contact Us Here
About Japanese Healthcare System

What you need to know about the healthcare system in Japan before using the data.
SERVICE

In addition to various web tools that allow you to easily conduct surveys via a browser using our medical database, we offer data provision services categorized into four types to meet your needs and challenges: "Analysis reports" "Datasets," "All Therapeutic Areas Data Provision Service," and "Specific Therapeutic Areas Data Provision Service.
![]()
© Medical Data Vision Co., Ltd. All Rights Reserved.