

Dataset? Some explanations about the way it is conceived, the various types existing and their applications in machine learning
Many people may have heard about datasets, and frequently, questions such as “What is a dataset?” or “How is it different from a database?” are raised but little is known about the details. Briefly said, a dataset is a collection of data arranged in a certain format to be used in various fields for various purposes.
This article provides an overview. In addition to introducing the types of datasets used in machine learning and how to create them, we also introduce the benefits of using high-quality datasets.
What is Dataset?
A dataset is a collection of data that has been collected for a purpose and arranged in a certain format. Generally, in the field of statistical machine learning, it refers to a collection of data that is processed by a program.
There are various types of datasets, such as image datasets, video datasets, audio datasets, text datasets, economic and financial datasets, medical datasets, and tourism datasets.
Among them, the image dataset called MNIST is quite representative; it is a collection of 70,000 images of handwritten digits from 0 to 9. It is widely used for learning and for evaluation in the field of machine learning in image recognition.
Each piece of data that makes up a dataset is called a “record” or “data point.” Machine learning builds a model for the target by entering records one by one from the collected data set and calculating them.
Dataset and Database, what is the difference?
A dataset is a collection of data regrouped for a certain purpose, while a database is a collection of information organized so that it can be searched and stored easily based on certain rules.
A dataset can be easily understood if we imagine it as “a container for holding records retrieved from a database in memory”. It is possible to process by extracting the data necessary for machine learning from the database and gathering them in a dataset.
Related articless
What is Database Construction? The Benefits and the Process of Building a Database
What a Medical Database is and How We Can Use it
Types of datasets used in machine learning
There are three types of datasets used in machine learning: training set, validation set, and test set. The features and roles of each dataset are explained below.
Training set
The training set is the largest dataset used initially.
By giving machine learning algorithms, it can be used to train development models. Build a base model. Model learning is based on this training set.
Validation set
A validation set is a dataset used to tune the hyperparameters that control a machine learning algorithm after it has been trained on the training set. We train different hyperparameters on the training set, use the validation set, and then pick the one that performs best.
Test set
A test set is a dataset used to check the accuracy of a model judged to perform well on the validation set. It is often used in the final stages of verifying data accuracy, and is only used for performance testing.
It is often confused with the validation set, but if you use the validation set that has already been used, you will get different values from the original values, so we will use the unused test set to verify the accuracy.
How to create a dataset
We would like to explain how to create a dataset following three steps:
1. Clarify the issues of the model
When creating a dataset, it is important to first clarify the problem of the model.
It is important to get a clear view of “what is the purpose of introducing machine learning” and “what problems should be solved by introducing machine learning”.
It is difficult to create a data set that fits the purpose if the problem is not specific. For this reason, we recommend that you specify the model issue, such as “I want to introduce machine learning to improve work efficiency” or “I want to introduce machine learning to help medical research.”
2. Collect data
Once you have defined the model’s challenges, we enter the step of data collection.
To improve the machine learning output, the quality and quantity of collected data are important.
A phenomenon known as “overfitting” can occur when not enough data is collected. Overfitting is the result of a model that fits the training data, but fails to predict new data. In order to prevent overfitting, it is necessary to increase the amount of data little by little.
3. Add annotations
After collecting the data, it is important to annotate them.
Annotation refers to “tagging”. In machine learning, it is common to tag various data. By annotating a huge amount of data and adding training data with questions and answers added as information, it is possible to determine which model is correct.
5 points to note when creating datasets
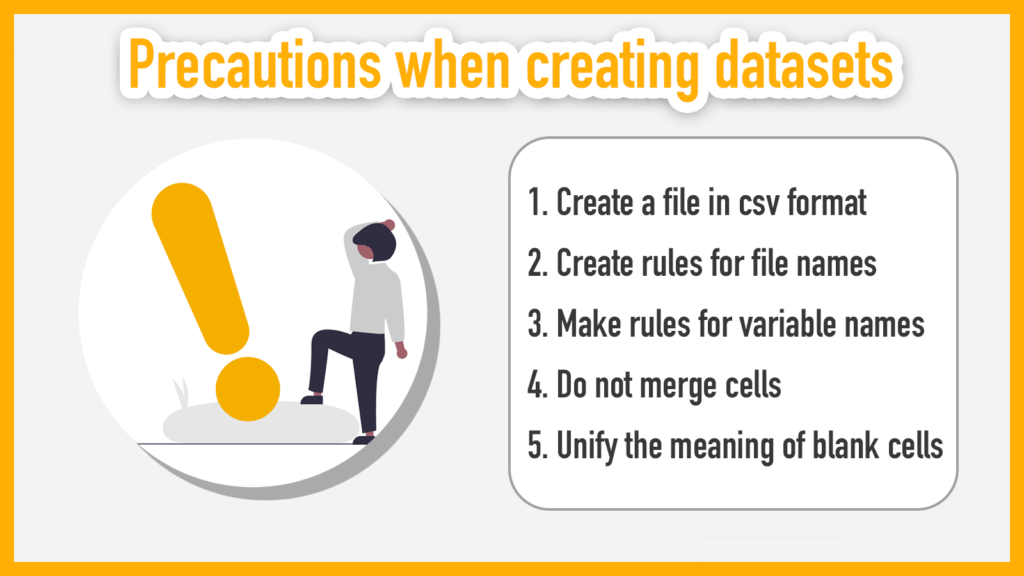
There are five things to keep in mind when creating datasets as described below:
1. Create Excel data as a csv file
When exporting the data used in the dataset from Excel, it is important to create a csv file.
The default file type when working in Excel and saving is .xls or .xlsx format. However, these formats are difficult to handle because they include information derived from Excel when performing data analysis and machine learning. A csv file is best for easy handling and smooth checking and correction of the dataset.
2. Create rules for file names
It is important to set rules for file names. As data creation progresses, the number of files to be handled increases. At this time, if the file name is randomly assigned, it becomes difficult to manage the data, and extraction may become complicated. Therefore, it is good to set simple rule the file name. It makes data easier to manage and reduces extraction time.
3. Create rules for variable names
There are rules for how to name variables, and if you use a name that goes against the rules, a calculation error may occur. Therefore, it is recommended to set the name of the variable and the name of the dataset according to the rules. It is also important to use names that are as descriptive as possible.
4. Do not merge cells
You should avoid using Excel’s cell merging feature when merging datasets. This is because if you merge the cells, you will not be able to read the data. The same is true for sample name and feature name cells, so enter them as they are without merging them in any cell.
5. Unify the meaning of blank cells
You must ensure to unify the meaning of the blank cells that occur when you put together a dataset. At the stage of creating the dataset, blank cells with no input occur. Blank cells are not a problem. However, if the data set is blank when loaded, it’s hard to tell if you didn’t make any measurements or if you made a measurement and the result was zero.
Therefore, you should try and assign only one meaning to blank cells, such as “samples with zero measurement results”.
Advantages of using high-quality datasets
Using high-quality datasets when doing machine learning also improves the quality of machine learning. A high-quality data set is essential for high-precision forecasting and analysis. The use of high-quality datasets will lead to more efficient operations and the creation of new services.
At Medical Data Vision Co., Ltd., we ask customers about their purpose of use, and then we provide a dataset that collects and processes patient data to be analyzed. The provided datasets are used by pharmaceutical companies, medical and material equipment manufacturers, academia, public research institutes, etc. for purposes such as writing papers and presenting at academic conferences.
If you are considering using a dataset, please feel free to contact us.
For More Information, Please Contact Us Here
About Japanese Healthcare System

What you need to know about the healthcare system in Japan before using the data.
SERVICE

In addition to various web tools that allow you to easily conduct surveys via a browser using our medical database, we offer data provision services categorized into four types to meet your needs and challenges: "Analysis reports" "Datasets," "All Therapeutic Areas Data Provision Service," and "Specific Therapeutic Areas Data Provision Service.
![]()
© Medical Data Vision Co., Ltd. All Rights Reserved.